Mastering Hadoop3: Name node & Data node
Chapter 1
Origins
아파치 루씬(정보 검색, 색인 및 검색) > 아파치 너치(검색엔진, 웹 크롤러 HTML 구문 분석)
scalability의 부족.
Doug와 Mike는(루씬 개발자) 3가지 특징을 가지는 시스템을 원했음
- 내결함성
- 로드밸런싱
- 데이터 손실(고가용성)
이 시점에 구글에서 GFS 발표, NDFS(Nutch Distribuited File System) 개발 시작(2004년)
block과 replication 개념을 이용.
Block은 파일을 64MB chunks(사이즈 조정가능) 로 분해하고 그 블록을 3번 복사.
맵 리듀스
NDFS 에 저장된 데이터를 처리 할 수 있는 알고리즘을 개발.
기계의 개수를 두배로 늘리면 두배의 성능이 나오는것을 기대함.
그 시기에 구글이 MapReduce를 배포함.
맵 리듀스의 특성
- Parallelism (평행성)
- 내결함성
- Data Locality
- (프로그램이 있는 곳에 데이터를 가져오는 것이 아닌 데이터가 있는곳에서 프로그램을 실행)
맵리듀스는 2005년에 넛치에 통합되었다.
2006년에 HDFS(Hadoop Distributed File System) 프로젝트를 시작 했으며
이는 NDFS, MapReduce, Hadoop Common 등의 이름을 따서 지어졌다.
네임노드: 메타데이터 정보를 관리.
MapReduce 엔진: Job tracker, Task tracker, 확장성이 40,000 노드 까지밖에 안됌.
이 문제를 해결하기 위해 YARN이 하둡2에 등장 > 확장성 문제와 자원관리 job 을 극복.
하둡 3의 원동력
- 버그 수정, 성능향상
- 오픈 소스 커뮤니티에서 많은 수정사항이 있었고 이를 다 반영하기 위해 하둡3로 릴리즈
- 데이터 복제 팩터로 인한 오버헤드
-
erasure coding을 이용해 해결 (데이터 사이즈를 잘 결정해야 namenode에 부하 x)
- YARN Timeline service 향상
- NameNode 고가용성 향상
- 하둡의 Default 포트 그대로 사용
- HDFS diskbalncer
하둡 플랫폼 Logical view
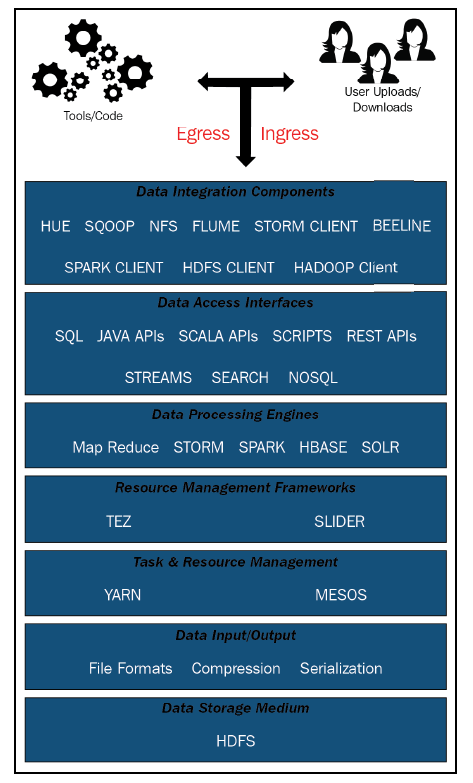
- Ingress/egress/processing - 자동화 가능
- Ingesting data
- Reading data
- Processing already ingested data
- Data integration components
스쿱, JAVA Hadoop Client 등.. - Data access interfaces
다양한 언어로 하둡 데이터에 접근할수 있게 해줌. - Data Processing Engines
하둡에 저장된 데이터를 연산할 수 있는 다양한 엔진. MapReduce 는 RAM 메모리를 보존하고 디스크 I/O를 더 쓰는 점에서 배치 데이터 처리에 적합하고, Spark 는 disk I/O-bound 가 적고 램 메모리를 더 사용하는 점에서 실시간 데이터나 micro-batch 처리에 적합하다. - Resource management frameworks
Hadoop의 작업 및 작업 스케줄링을 위해 추상 API를 노출하여 기본 리소스 관리자(YARN, Mesos)와 상호 작용 - Task and resource management
클러스터 내에서 동시에 실행되는 서로 다른 애플리케이션에서 대규모 클러스터 머신을 공유
YARN은 Unix process. MESOS는 Linux-container-based. - Data input/output
- Data Storage Medium
HDFS: JAVA 기반, 유닉스 파일시스템
Chapter 2
하둡 HDFS에 대해 자세히 알아보자
HDFS의 특징
- 내결함성
- 실시간 데이터 접근
- 확장성
- 간단함
- 고가용성
하둡 플랫폼은 분산 저장소와 분산 처리, 두개의 논리적 구성으로 되어있다.
HDFS 가 분산 저장소 를, MapReduce와 YARN-호환 프레임워크들 이 분산 처리 능력을 제공한다.
HDFS logical architecture
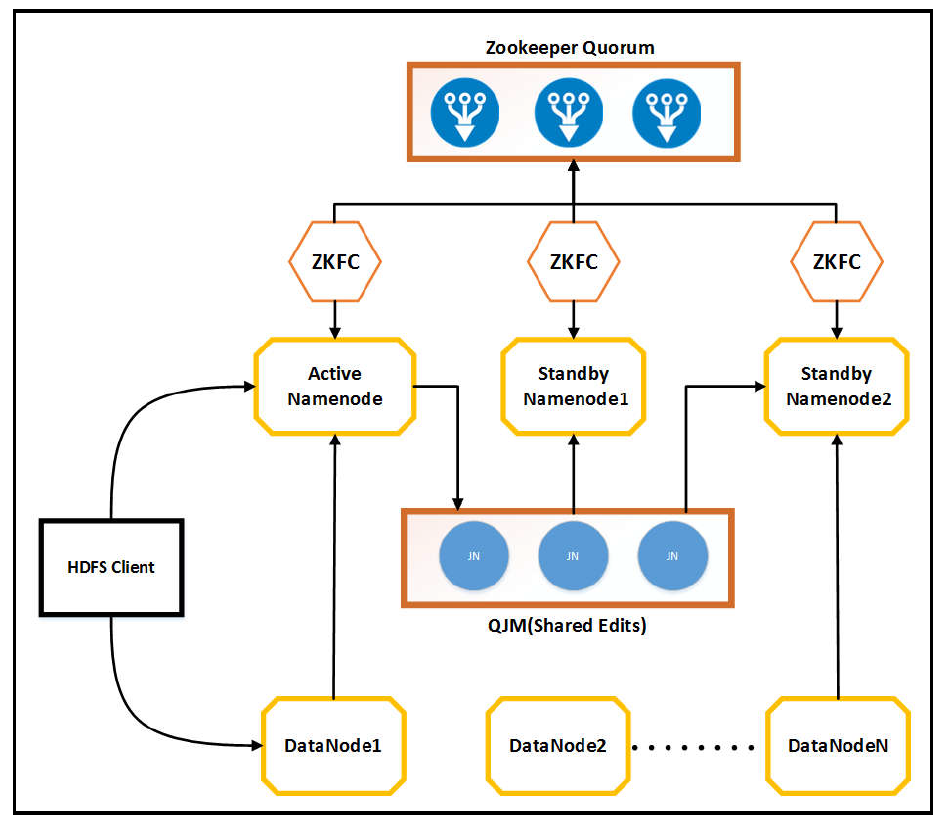
이 아키텍쳐는 간단하게 데이터 그룹과 관리 그룹, 두가지 그룹으로 나눌 수 있다.
데이터 그룹은 파일 저장소의 처리/구성요소를 포함하고
관리 그룹은 데이터 오퍼레이션(읽기,쓰기,자르기,삭제)을 관리하는 처리/구성요소를 포함한다.
데이터 그룹: Data blocks, replication, checkpoints, file metadata
관리 그룹: NameNodes, DataNodes, JournalNodes, Zookeepers
관리 그룹(Management group)의 구성요소
-
NameNode: HDFS는 마스터-슬레이브 구조이고 네임노드는 마스터의 역할을 한다. 네임노드는 데이터의 메타데이터를 관리하는데 File System namespace, fsimage files, edit logs files 이렇게 세가지의 정보를 저장한다.
fsimage는 파일 시스템의 한 시점의 상태를 저장
edit log는 fsimage가 저장된 이후의 HDFS의 모든 파일의 변화를 저장.
fsimage와 edit log를 병합하는것을 체크포인팅이라고 한다. -
DataNode: HDFS의 구조에서 슬레이브 역할을 한다. 네임노드나 HDFS 클라이언트로부터 받은 data block operation을 수행(생성, 수정, 삭제)
processing job은 MapReduce등을 이용하고 block의 정보를 네임노드에 다시 전달한다. 또한 복제가 있는 데이터 노드끼리 통신 할 수 있다. -
JournalNode: 저널노드는 활성된 네임노드와 대기중인 네임노드 사이에서 edit log와 HDFS 메타데이터를 관리하는 역할이다.
쓰기 동시성 제어를 통해 활성된 하나의 네임노드가 edit log를 작성하도록 한다. -
Zookeeper failover controllers(ZKFC): 하둡은 네임노드의 고가용성을 유지하기 위해 두가지 구성요소를 소개한다 Zookeeper Quorum과 ZKFC이다.
주키퍼는 네임노드의 health와 connectivity의 정보를 점검하며 네임노드가 만료되면 재시작하는 역할을 수행한다.
failure이나 crash 이벤트가 발생한다면 만료된 세션은 failed 네임노드에 의해 재시작 되지 못하며 이때 주키퍼가 대기중인 네임노드에 failover 프로세스를 시작한다. 이 주키퍼의 클라이언트가 ZKFC이며 네임노드의 건강을 모니터링하고 세션을 관리하며 쓰기 동시성 제어를 한다.
데이터 그룹(Data group)의 개념
데이터 그룹은 Block, Replication 두개의 개념이 있다.
-
Block은 HDFS가 한번에 읽거나 쓸수 있는 최소 데이터의 양을 정의한다.
기본 block의 크기는 64MB나 128MB 이며 이는 Unix-level 파일시스템과 비교 했을 때 더 큰 사이즈다.
이렇게 큰 블록 사이즈를 사용하는 이유가 여러가지 있는데, 첫번째로 만약 블록의 사이즈가 너무 작다면 네임노드가 관리해야하는 메타데이터가 많아져 메모리가 모자라는 현상이 발생한다. 큰 사이즈의 블록은 메타데이터를 효과적으로 관리할 수 있다.
두번째로 데이터 블록이 클 경우 Hadoop의 처리량이 증가한다. -
Replication 하둡의 복제 펙터는 기본적으로 3이다. 1개의 파일에 대해 총 3개의 데이터 블록을 저장하는 것이다. 복제된 데이터 블록이 어디에 저장 되는 것도 중요한데 rack-aware 정책을 따른다. 같은 랙에 있는것과 다른 랙에 있는것이 네트워크 대역폭의 차이때문에 속도에 차이가 있기 때문에 데이터는 다음과 같이 저장된다.
Writer가 있는 local machine에 한개, 그와 같은 랙에 있는 데이터 노드에 한개, 다른 랙에 있는 데이터 노드에 한개. HDFS는 랙 실패가 노드 실패보다 적을 것이라 생각하기 때문에 두개의 다른 랙에만 저장이된다. 이렇게 저장되면 로컬 머신에있는 데이터 노드가 실패 했을시에는 빠르게 같은 랙에 있는 데이터 블록을 참조하고, 데이터가 있는 하나의 랙이 실패하면 두개가 모두 실패하지 않는이상 다른 랙을 참조하면 되기 때문에, 효율성과 고가용성을 모두 고려한 설계라고 생각한다.
HDFS communication architecture
지금 까지 네임노드, 데이터 노드 등 HDFS 컴포넌트들을 설명했는데 이것들이 실제로 어떻게 통신하는지에 대해 알아보자. 기본적으로 TCP/IP 프로토콜을 이용하며 서로 다른 통신방식으로 래핑되어있다.
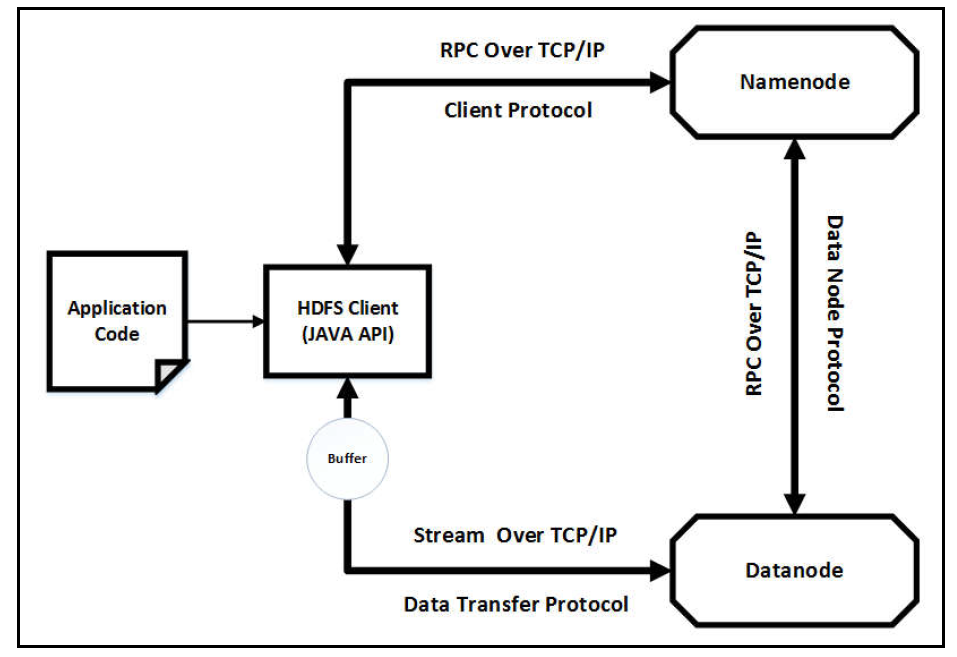
- Client Protocol : HDFS Client와 Namenode server간의 통신 방식이다. 원격 프로시저 호출 방식(RPC)을 이용해 네임노드의 지정된 포트를 TCP 프로토콜을 사용해 통신한다. 주요 메서드는 다음과 같다.
- create : HDFS 네임스페이스에 빈 파일 생성
- append : 파일 뒤에 더함
- setReplication : 복제본 생성
- addBlock : 추가블록 생성
- Data Transfer Protocol : HDFS Client는 네임 노드로부터 메타데이터를 받고나서 읽기,쓰기를 하기위해 데이터노드와 통신한다. 이 통신 타입이 가장 무거운 작업을 하기 때문에 원격 프로시저 호출이 아닌 스트리밍 프로토콜을 사용한다. 주요 메서드는 다음과 같다.
- readBlock : 데이터 노드에서 데이터 블록을 읽음
- writeBlock : 데이터 노드에 데이터 블록을 씀
- transferBlock : 데이터 블록을 다른 데이터 노드로 옮김
- blockChecksum : 데이터 블록의 체크섬을 가져옴
- Data Node Protocol : 네임 노드와 데이터 노드간의 통신이다. 데이터 노드에서 ‘operation, health, storage information’ 등을 네임 노드에 전달하기 위해서 사용하기 때문에 단방향 프로토콜이다. 데이터 노드가 request를 시작하고 네임 노드는 해당 request에 반응을 한다. 주요 메서드는 다음과 같다.
- registerDatanode : 다시 실행되거나 새로 만들어진 데이터 노드를 네임 노드에 등록
- sendHeartbeat : 데이터 노드가 잘 작동중인것을 전달.
- blockReport : 데이터 노드의 블록 관련 정보를 네임 노드에 전달하면 네임 노드는 쓸모가 없는 블록을 판단하고 삭제하도록 지시한다.
NameNode internals
HDFS 유저들은 API를 이용해 read/write/create/delete 동작만 사용하면 되지만 그 뒤에서는 복잡한 작업들이 실행된다. 네임 노드는 이 복잡한 작업들의 중심요소이며 다음과 같은 작업들을 한다.
- HDFS 에 저장된 파일과 디렉터리의 메타데이터를 유지보수한다. 메타데이터는 파일 생성/수정 타임스탬프와 ACL, 블록과 복제 저장소 정보, 파일의 현재 상태 등을 포함한다.
- 파일, 디렉터리에 저장된 ACL을 이용한 파일 작업과 어떤 블록과 복제본들이 어떤 데이터 노드에 의해 다뤄질지를 결정 한다.
- Client에게 데이터 블록의 정보 전달
- 손상된 데이터 블록을 삭제하도록 데이터 노드에게 명령을 내리고 healty 데이터 노드들의 목록을 관리한다.
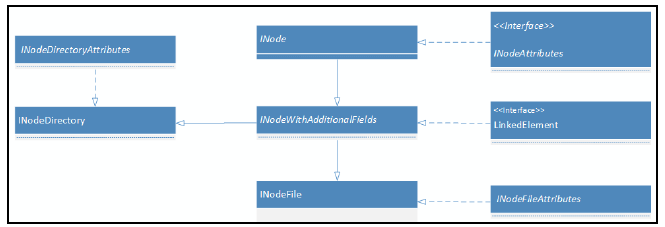
네임 노드는 INodes 라는 데이터 구조를 메모리에서 관리한다. INode의 다이어 그램은 다음 사진과 같다.
Data locality and rack awareness
위의 데이터 그룹의 복제본 정책에서 본 것 과 같이 하둡은 3개의 복제본을 사용하는데 이것을 Data Local, Rack Local, Off rack 에 저장 함으로써 data locality를 만족한다.
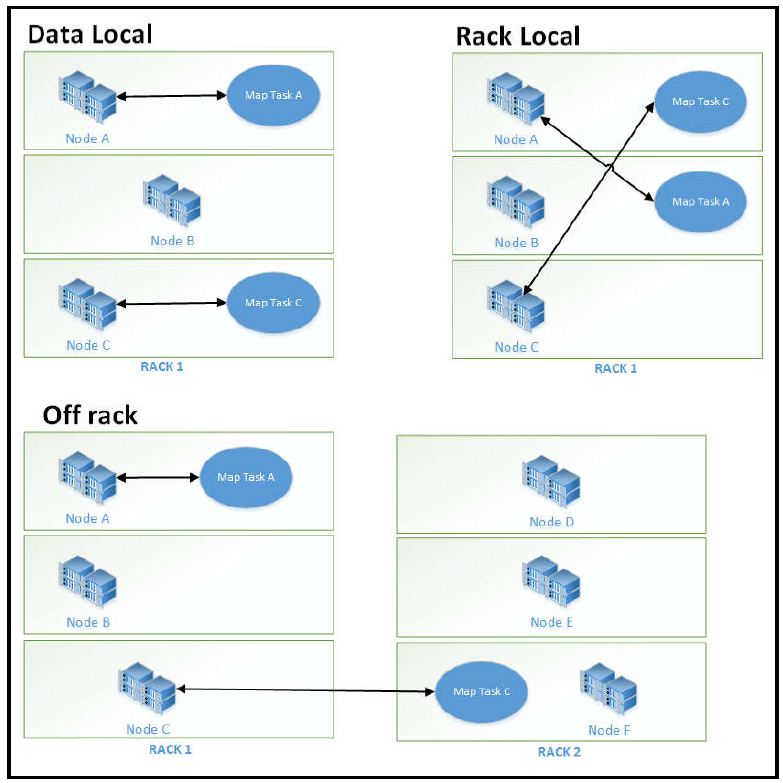
Data Node internals
- Heartbeat : 일정한 심장박동을 네임 노드에게 전달해 정상적으로 작동하는지 알려주고 client로 부터 쓰기/읽기/삭제와 같은 요청을 수행 할 수 있다는것을 알려줌.
만약 심장박동이 오지 않는다면 네임 노드는 해당 데이터 노드를 사용하지 않음. - Read/Write : client는 네임 노드에 요청을 보내고 네임 노드는 사용 가능한 데이터 노드의 목록을 준다.
- Replication and block report : 복제본 생성중에 하나의 데이터 노드는 다른 데이터 노드로 부터 쓰기 요청을 받는다. 데이터 노드는 주기적으로 block report 를 네임 노드에게 전달함.
Quorum Journal Manager
QJM 은 각각의 네임 노드에서 작동하고 저널 노드와 RPC를 이용해 통신하는 역할이다. QJM 은 저널 노드에 쓰기를 할 때 다음과 같은 동작을 한다.
- 네임노드가 두개 이상 작동 하더라도 writer가 독립적으로 edit logs를 작성 하도록 함.
- 모든 저널 노드를 동기화.
- 앞의 두가지중 하나를 만족하면 새로운 로그 세그먼트를 시작해 로그를 편집함.
- writer는 현재 배치 편집내용을 클러스터의 모든 저널 노드에 전달하고 쓰기 성공으로 간주하기 전에 모든 저널 노드의 quorum(정족수)에 기반해 확인을 기다림. 만약 응답을 하지 못한 저널노드가 있다면 OutOfSync 로 지정되고 현재 버젼에서는 사용되지 않음.
- QJM은 RPC 요청을 보내 저널 노드가 로그 segmentation을 끝내도록함. 저널 노드 quorum들의 확인을 받은 이후에 새로운 log sement를 시작.
QJM은 두개 이상의 네임노드가 있을 때 고가용성을 달성하도록 도와준다.
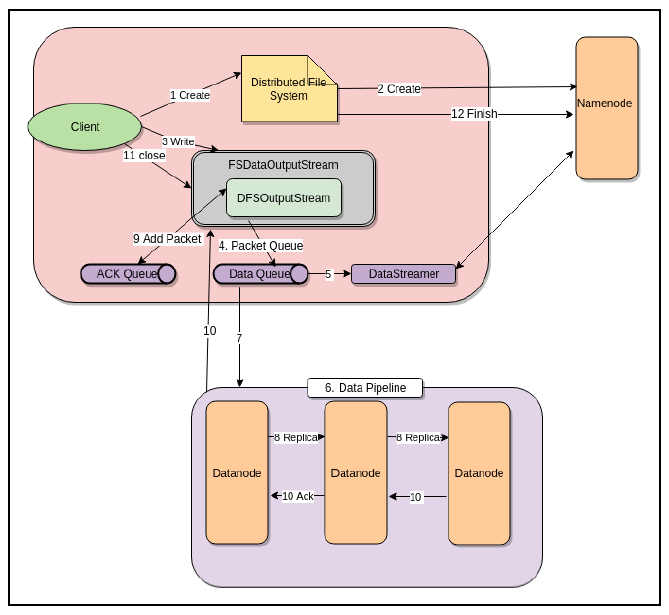
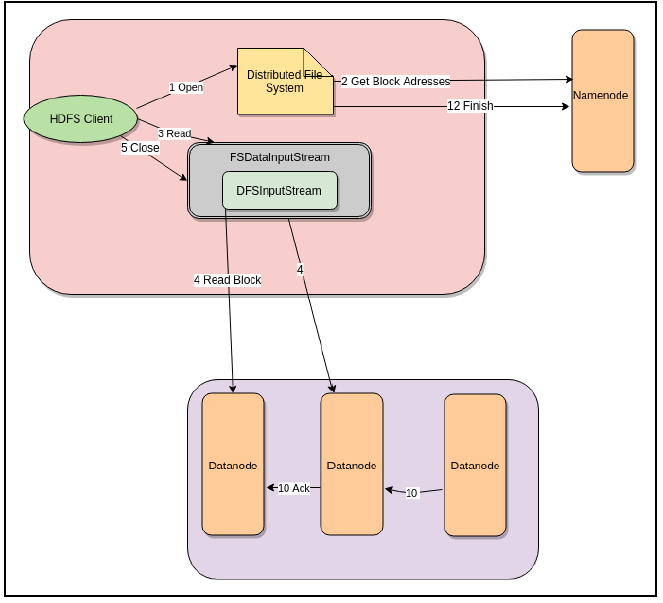
하둡의 쓰기, 읽기 워크 플로우
쓰기
읽기
댓글남기기